Content of the Report
In this report, Indiana cancer incidence and mortality numbers and age-adjusted and age-specific Indiana cancer incidence and mortality rates are presented for the year 1999 and the years 1995 through 1999 combined. Indiana Rates for the most common cancers are compared with national rates. For selected cancers, the African-American and white population rates are compared, as are state and county rates. Rates and numbers are reported for the state as a whole, and for each of the 92 counties, individually. Rates are also given for both sexes combined, and for males and females individually. The data utilized in calculating these rates was that available to the Indiana State Cancer Registry as of May 8, 2003. The North American Association of Central Cancer Registries (NAACCR) has specified a method of estimating completeness of case ascertainment, that is, calculating the actual number of cases reported as a percentage of the estimated number of cases to be diagnosed in Indiana in a given year. These are the completeness estimates for each of the five years covered in this report:
| 1995 | 1996 | 1997 | 1998 | 1999 |
| 91.1% | 91.2% | 94.4% | 98.9% | 95.8% |
By convention, cancer incidence rates do not include carcinoma in situ (with the exception of bladder cancer in situ), nor do they include basal and squamous cell carcinomas of the skin. The numbers and rates of reported cancers that appear in Sections 1, 3, 4 and 5 follow this convention, with the exception of Tables 3.n-7.
In contrast, in situ and skin cancers are included in the numbers given in Section 2 and in Tables 3.n-7, since these tables concern cancers diagnosed by stage. Thus, the total numbers in Section 2 do not match the other sections, but do match the numbers in Tables 3.n-7, with the exception of Table 3.2-7, which is limited to female breast cancer, whereas Section 2 displays numbers for both sexes.
Incidence Rates
The cancer incidence rate is the number of new cancers of a specific site or type occurring in a specified population during a year, expressed as the number of cancers per 100,000 people. It should be noted that the numerator of the rate can include multiple primary cancers occurring in one individual. This rate can be computed for each type of cancer, as well as for all cancers combined. These rates are age-standardized to the U.S. 2000 standard million population to allow for comparisons between groups (geographic or demographic) that have different age distributions.
When comparing rates over time or across different populations, crude rates (the number of newly-diagnosed cancer cases per 100,000 persons) can be misleading because differences in the age distributions of the various populations are not considered. Since cancer is age-dependent, the comparison of crude incidence rates from cancer can be especially deceptive.
Age-adjusted rates take into account the diverse age distributions of the populations. Valid comparisons between age-adjusted rates can be made, provided the same standard population and age groups have been used in the calculation of the rates. The direct method of adjustment was used to produce the age-adjusted rates for this report. In this method, the population is first divided into reasonably homogeneous age ranges and the age-specific rate is calculated for each age range; then each age-specific rate is weighted by multiplying it by the proportion of the standard population in the respective age group. The age-adjusted rate is the sum of the weighted age-specific rates.
For example, suppose there are 200,000 people aged 70 to 74 in the state, and this is 3.2% of the total state population (which would be 6,250,000 in this example), but only 2.7% of the standard population. Suppose further there are 64 cases in this age group of some type of cancer for which we want to calculate the rate. This is a crude rate of 32 per 100,000 for this age group. If this age group comprised only 2.7% of the state population, the same proportion as in the standard population, there would be only 168,750 people in this age group instead of 200,000. If this were the case and the crude rate were still 32 per 100,000, there would be only 54 cases instead of 64. In computing the age-adjusted rate, this age group is counted as if there were only 54 cases, since the additional cases are due to the increased proportion of people in this age group.
Conversely, suppose there are 400,000 people aged 20-24 in the state, which is 6.4% of the total state population, and suppose this age group comprises 7.2% of the standard population. Suppose further there are 16 cases in this age group of the type of cancer we're concerned with. This is a crude rate of 4 per 100,000 for this age group. If the percentage of people in this age group were the same as in the standard population, it would consist of 450,000 people instead of 400,000. If this were the case and the crude rate were still 4 per 100,000, there would be 18 cases instead of 16. In computing the age-adjusted rate, this age group is counted as if there were 18 cases, since the smaller number of cases is due to the decreased proportion of people in this age group.
Changing to the 2000 Standard Million Population
The U.S. 2000 standard million is the proportion of each age group in the United States population in the year 2000 such that the total of all the age groups is one million. For example, children from birth through fours years of age make up 69,135 of the standard million, so of every million people in the U.S. in 2000, 69,135 of them are children aged 0 to 4.. Put another way, children in this age group made up 6.9135% of the U.S. population in 2000.
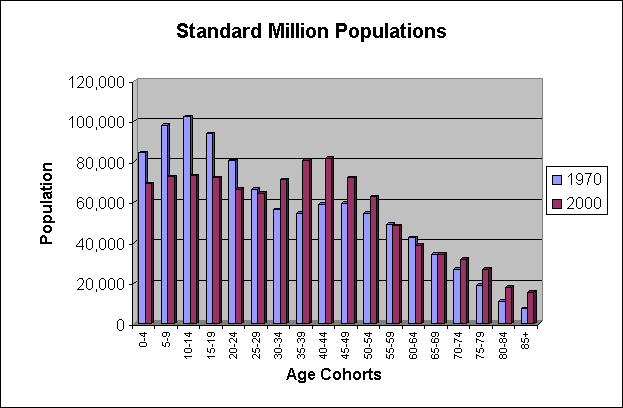
For data prior to 1999, rates were calculated with the U.S. 1970 standard million population. Beginning with 1999 data, the 2000 standard is used. This has a very noticeable impact on the age-adjusted rates, because the distribution of the population has shifted toward the older age cohorts, as shown in the following table. This same data is shown graphically in the chart below it. Since cancer occurs most frequently in older people, using the 2000 standard, which contains a greater proportion of older people, will result in higher age-adjusted rates than if the 1970 standard is used.
Two important trends have affected the change in age distribution. One is the aging of the baby boom generation (usually considered to be those born between 1946 and 1964). In 1970, this cohort ranged in age from 6 to 24, while in 2000 they ranged in age from 36 to 54. The other is the increasing longevity of people in general. The proportion of people living past 70 increased by more than 40% between 1970 and 2000, while the proportion living past 85 more than doubled.
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The trend towards an aging population means that even if age-specific rates (that is, the rates within each age group) remain constant, the overall rate will go up just because there are more people in the older groups where cancer is much more common. Age-adjusting mitigates this effect and allows comparison between different populations, provided the same standard is used.
Age-adjusted rates from previous annual reports that use the 1970 standard cannot be compared with the age-adjusted rates in this report, because of the change in the standard used to calculate the rates. Consequently, Section 4 provides rates from 1995 through 1999, all age-adjusted to the 2000 standard, thereby allowing valid comparisons to be made. Moreover, since the 2000 standard has been adopted nationwide, it's possible to compare Indiana's rates with those of other states, since they all use the same standard.
Rates based on small numbers of events over a given period of time or for sparsely populated geographic areas should be viewed with caution. These rates show considerable random variation and are considered "unstable," which limits their usefulness in comparisons and estimation of rare occurrences.
In this report, by convention, whenever the number of cases of any type of cancer is less than 5 at the county level, the actual number is not reported to protect the privacy of these individuals. An asterisk (*) will denote this in Section 5. If the number of cases of any type of cancer is less than twenty, the rate generated is considered "unstable" and is marked with a double asterisk (**) when given in the tables.
Even when rates are based on a large numbers of events, there is still some degree of random variation. Thus the calculated rate may not be the "true" rate. Nonetheless it is possible to calculate the end points of an interval such that the probability that the true rate is outside the interval is less than some given value. For example, if the calculated rate for a particular type of cancer is 100 cases per 100,000 people, it can be calculated that the probability is less than 0.05 that the true rate is less than (say) 97 or greater than 104. Thus we are 95% confident that the true rate is between 97 and 104. The bar charts in Sections 1 and 2 use a bar to show the calculated rates and a horizontal I-beam to show the confidence interval, as shown here:
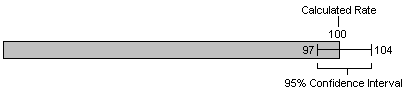
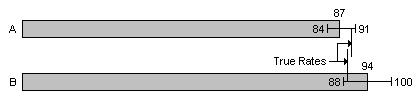
Because the calculated rate is not necessarily the true rate, it is not sufficient to compare the rates of two areas to determine if one area has a higher rate than the other. For example, suppose Area A has a calculated rate of 87 and Area B has a calculated rate of 94. Area B appears to have a higher rate. But suppose the 95% confidence intervals are computed and it turns out that we are 95% confident that Area A's rate is between 84 and 91, and we are 95% confident that Area B's rate is between 88 and 100. Then the confidence intervals overlap, so it's possible A's true rate is 90 and B's is 89, and it may have been a mistake to assume Area B has a higher rate, as shown here:
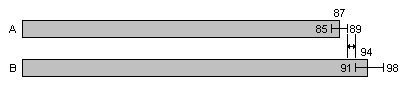
On the other hand, if A's 95% confidence interval turns out to be 85 to 89, and B's 91 to 98, then the confidence intervals do not overlap. Thus B's true rate must be greater than A's, as shown below, unless A's true rates lies outside its confidence interval (and there's only a 5% chance of that), or B's true rates lies outside its confidence interval (and there's only a 5% chance of that).
The maps in Section 3 are shaded to show county rates that are higher, lower, or similar to the rate for Indiana as a whole. The rates are considered similar if the 95% confidence intervals overlap. In other words, if it cannot be said with at least 95% confidence that one rate is higher than the other, they are considered similar. Rates based on fewer than 20 cases are excluded from comparison.
Formulas
A crude rate is the number of cases per 100,000 in a given population, as given by the following formula:
![]()
The following is the formula used to calculate the age-adjusted rate for age groups x through y:
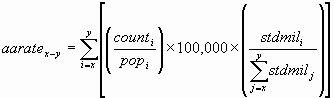
where counti is the number of cases for the ith age group, popi is the relevant population for the same age group, and stdmili is the standard population for the same age group. The 1970 standard population is given in Appendix D, which shows the population divided into 18 age cohorts, each with a range of 5 years, except the last, which includes everyone 85 and over. In this report, age-adjusted rates are calculated for all age groups, so in the above formula, x =1 (the first age group) and y = 18 (the last age group).
The formula for computing the end-points of a confidence interval for age-adjusted rates is somewhat complex. Suppose that the age-adjusted rate is comprised of age groups x through y, and let:
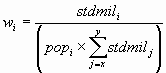
![]()
![]()
The endpoints of a (1 - p) × 100% confidence interval are calculated as:
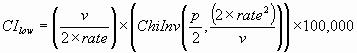
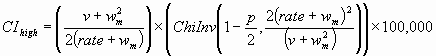
where ChiInv(p,n) is the inverse of the chi-squared distribution function evaluated at p and with n degrees of freedom, and we define ChiInv(p,0) = 0.
This method for calculating the confidence interval produces similar confidence limits to the standard normal approximation when the counts are large and the population being studied is similar to the standard population. In other cases, the above method is more likely to ensure proper coverage.
Note: The rate used in the above formulas for the confidence interval endpoints is not per 100,000 population.
All of the above formulas are taken from A Guide to Using SEER*Stat, Version 3.0, National Cancer Institute, Cancer Statistics Branch, DCCPS.